HERMES OPTIMUS v2.0
Revolutionary 30-50-12 hybrid architecture achieving 96.24% accuracy across 186 comprehensive robustness tests
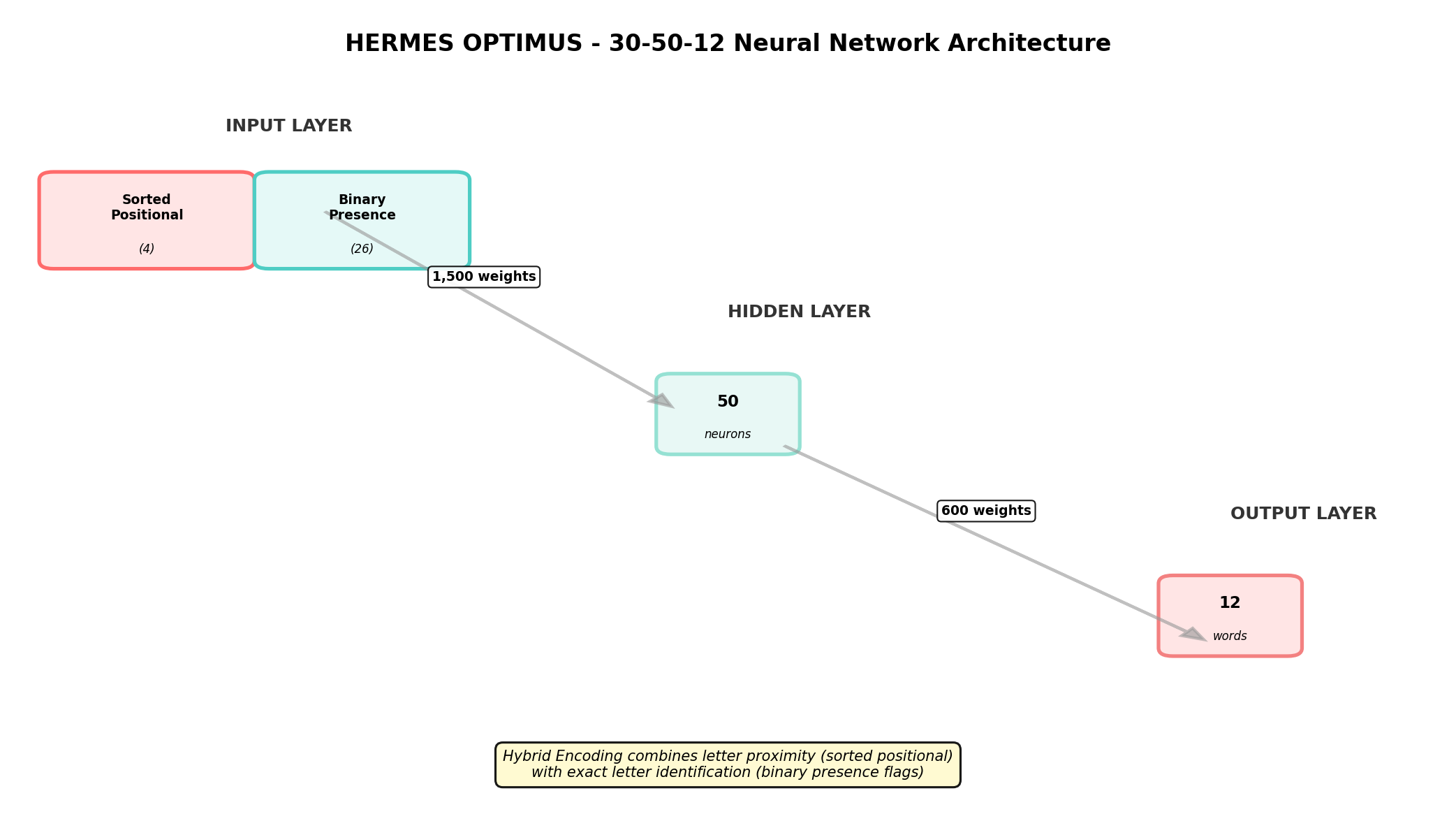
30-50-12 Neural Network Architecture
Click to enlarge
- Input Layer: 30 neurons
- Positions 0-3 (4 neurons): Sorted positional encoding (normalized values 0-1)
- Positions 4-29 (26 neurons): Binary presence flags for A-Z
- Hidden Layer: 50 neurons with sigmoid activation
- Output Layer: 12 neurons (one for each target word)
The v2.0 architecture represents a fundamental evolution from the original 4-60-12 design. By expanding the input layer to 30 neurons and implementing hybrid encoding, the network achieves position-invariance (perfect scramble handling) while maintaining adjacency-awareness (keyboard typo tolerance).
Evolution from v1.0
v1.0: 4-60-12 Positional Architecture
- 4 input neurons (positional encoding only)
- 60 hidden neurons
- ~85% accuracy, struggled with scrambled words
v2.0: 30-50-12 Hybrid Architecture
- 30 input neurons (hybrid encoding: 4 positional + 26 binary)
- 50 hidden neurons (optimized for memory constraints)
- 96.24% accuracy across 186 comprehensive tests
Memory Optimization
Weight Matrix [I]:
30×50 = 1,500 weights
Weight Matrix [J]:
50×12 = 600 weights
Biases:
50 + 12 = 62 values
Total Memory:
~22.5KB (1.5KB remaining)
The architecture was precisely calibrated to fit within the TI-84's 24KB RAM limit. Reducing from 60 to 50 hidden neurons was necessary to accommodate the expanded 30-neuron input layer while maintaining sufficient overhead for program execution.